This week, the net’s been exploding with responses to James Bridle’s work on the New Aesthetic. Bruce Sterling set the fuse for this particular conflagration with his Essay on the New Aesthetic in Wired.
My own response, published in The Creator’s Project on Friday, was called What It’s Like to be a 21st Century Thing. I tried to put NA in the context of Object-Oriented Ontology arguing that NA “consists of visual artifacts we make to help us imagine the inner lives of our digital objects and also of the visual representations produced by our digital objects as a kind of pigeon language between their inaccessible inner lives and ours.” This is an approach I’m excited about and plan to flesh out more here soon.
Today, though, I want to engage in a bit of OOO ontography and close-looking as a way of responding to what I thought was one of the more interesting takes on Sterling’s essay.
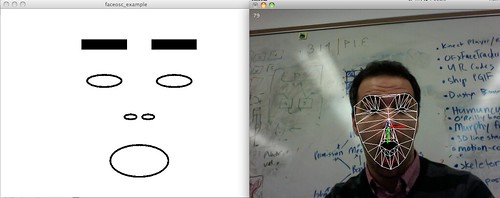
In his post Why the New Aesthetic isn’t about 8bit retro, the Robot Readable World, computer vision and pirates, Rev Dan Catt tries to address the 8-bit quality of much New Aesthetic visual work. Specifically, he’s trying to answer a criticism of NA as retro, a throwback to “the colors and 8 bit graphics of the 80s” as Tom Coates put it.
For Catt that resemblance comes from the primitive state of computer vision today. “Computer vision isn’t very advanced, to exist with machines in the real world we need to mark up the world to help them see”, he says. In other words, the current limitations of computer vision algorithms require intentionally designed bold blocky 8-bit graphics for them to function. And therefore the markers we design to meet this requirement end up looking like primitive computer graphics, which resulted from similar technical limitations in the systems that produced them. As Catt says, “put another way, current computer vision can probably ‘see’ computer graphics from around 20–30 years ago.”
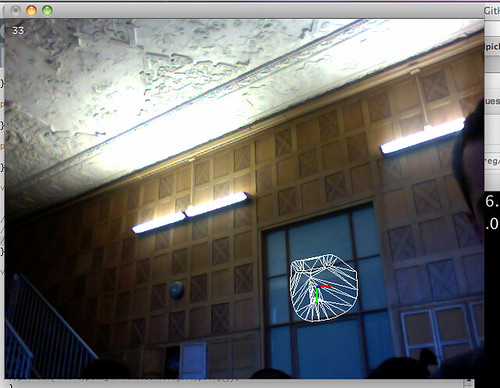
In a conversation about this idea, Kyle McDonald argued that Catt’s taking the comparison too far. While there is a functional comparison between the current state of computer vision and the state of computer graphics in the 80s, the actual markers we’re using in CV work today don’t much resemble 8-bit graphics aesthetically.
To explore this idea, Kyle and I decided to put together a collection of as many different kinds of markers as we could think of along with links to the algorithms and processes that create and track them (though I’m sure there are many we’ve missed – more contributions are welcome in the comments). It was our hope that such a collection might widen the New Aesthetic visual vocabulary by adding additional ingredients as well as focusing some attention on the actual computational techniques used to create and track these images. Since so many of us were raised looking at 8-bit video games and graphics I think it quite helps to look at the actual markers themselves in their surprising variety rather than just filing them away with Pitfall Harry’s rope, Mario’s mushroom, and Donkey Kong’s barrel, which we already know so well.
So, what do real CV markers actually look like? Browse the images and links below to see for yourself, but I’ll make a few quick general characterizations. There is a lot of high contrast black and white as well as stark geometry that emphasizes edges. However the grid that characterizes 8-bit images and games is nearly never kept fully in tact. Most of the marker designs are specifically trying to defeat repetition in favor of identifying a few specific features. Curves and circles are nearly as common as squares and grids.
I’d love to collect more technical links about the tracking techniques associated with each of these kinds of markers. So jump in with the comments if you’ve got suggestions.
figcaption {
display: none;
}
OpenCV calibration checker pattern for homography

Reactivision

(Original paper: Improved Topological Fiducial Tracking in the reacTIVision System)
Graphtracker

(Original paper: Graphtracker: A topology projection invariant optical tracker)
Rune Tags

(Original paper: RUNE-Tag: a High Accuracy Fiducial Marker with Strong Occlusion Resilience)
Corner detection for calibration

Dot tracking markers
Traditional bar codes

Stacked bar code

Data Matrix 2D

Text EZCode

Data Glyphs

QR codes

Custom QR codes


Microsoft tags aka High Capacity Color Barcodes

Maxi Codes

Short Codes

Different flavors of Fiducial Markers




9-Point Landmark

Cantags

AR tracking marker for After Effects

ARTag markers

Retro-reflective motion capture markers

Hybrid marker approaches